About
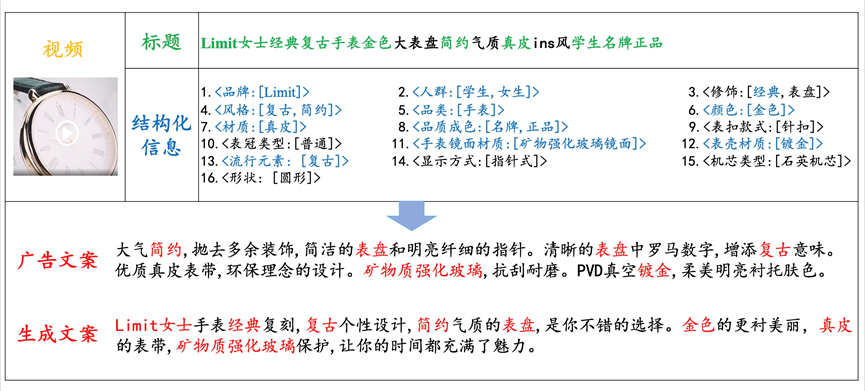
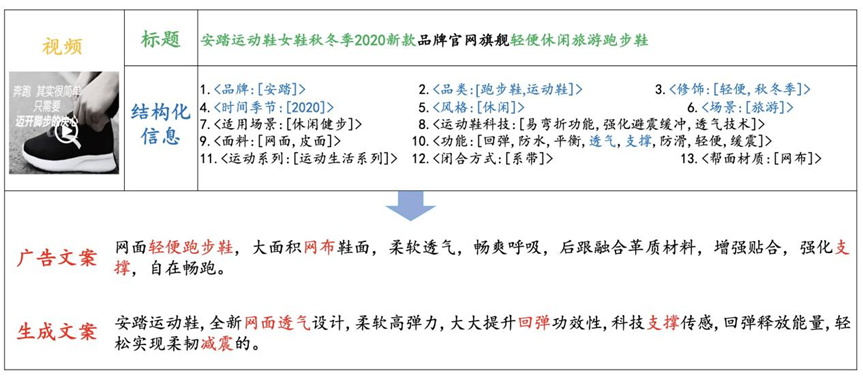
We present an e-commercial multi-modal advertising dataset, E-MMAD, which contains 120 thousand valid data elaborately picked out from 1.3 million real product examples in both Chinese and English. Our dataset sources are the Chinese largest e-commerce website shopping platform (www.taobao.com). Noticeably, it is one of the largest video captioning datasets in this field, in which each example has its product video (around 30 seconds), title, caption and structured information table that is observed to play a vital role in practice.
100,000 +
high-level multimodal data
4000 +
e-commercial product categories about various fields
300,000 +
Structure Information Words
Diversity
The real world advertising description is vivid and various. So we collect a large-scale high-quality and reliable e-commercial multimodal advertising dataset. It is one of the largest video captioning datasets in this field. E-MMAD is completely collected from human real life and carefully selected so that it is qualified to meet the needs of real life.